In early April I published a paper with an unfashionable claim: the AI industry is solving the wrong memory problem.
Everyone was optimizing recall. Bigger context windows, better vector search, smarter retrieval. All useful. All missing the point for a specific class of system, the kind I care about most.
Two days before my paper went live, Garry Tan open-sourced GBrain, his personal agent memory system. It crossed 5,000 GitHub stars in 24 hours. In June, Oracle's engineering blog published a piece on moving from RAG to AI memory systems: typed memory, promotion gates, scoped access control, replayable traces.
Three independent takes on the same problem, within one quarter. I don't want to overstate what that means, and I will be precise about it further down. But when a solo consultant in Mérida and Oracle's database engineering org reach for the same vocabulary in the same quarter without talking to each other, it is usually a sign that a problem is becoming visible.
Here is what I argued, where the industry landed, and what is still missing from everyone's version, including the big ones.
Recall is not continuity
Think about an AI system that has been working with your agency for six months. It knows your positioning. It helped define your ICP. It watched you revise pricing twice and reject two messaging angles before landing on the third.
Now ask it for help with a new campaign.
A recall-optimized system will retrieve something relevant. Maybe the current ICP. Maybe the one you superseded in February, since they are semantically almost identical and vector search cannot tell operative truth from historical truth. Maybe it resurfaces a positioning angle you explicitly killed, because that discussion was long and detailed and ranks well.
None of these are retrieval failures in the narrow sense. The system found relevant content. They are continuity failures. The system retrieved the right words from the wrong reality.
In the paper I called this the continuity burden. A system that inhabits a durable expert role, with a bounded domain, persisting across sessions, accumulating validated work, is not judged by whether it can find prior information. It is judged by whether it remains the same expert over time. Whether it uses current truths instead of stale ones. Whether decisions, once made, stay made.
When these systems fail, they do not forget. They drift. And drift is worse than forgetting, because it looks like memory.
What I proposed
The paper's core claim is that the ingredients for solving this all exist already. Retrieval, temporal stores, episodic memory, governance mechanisms. They have just been treated as separate optional enhancements bolted onto a recall-oriented base. That separation is itself the problem. Once a system is designed to hold an expert role over time, these stop being independent improvements and become one integrated architectural requirement.
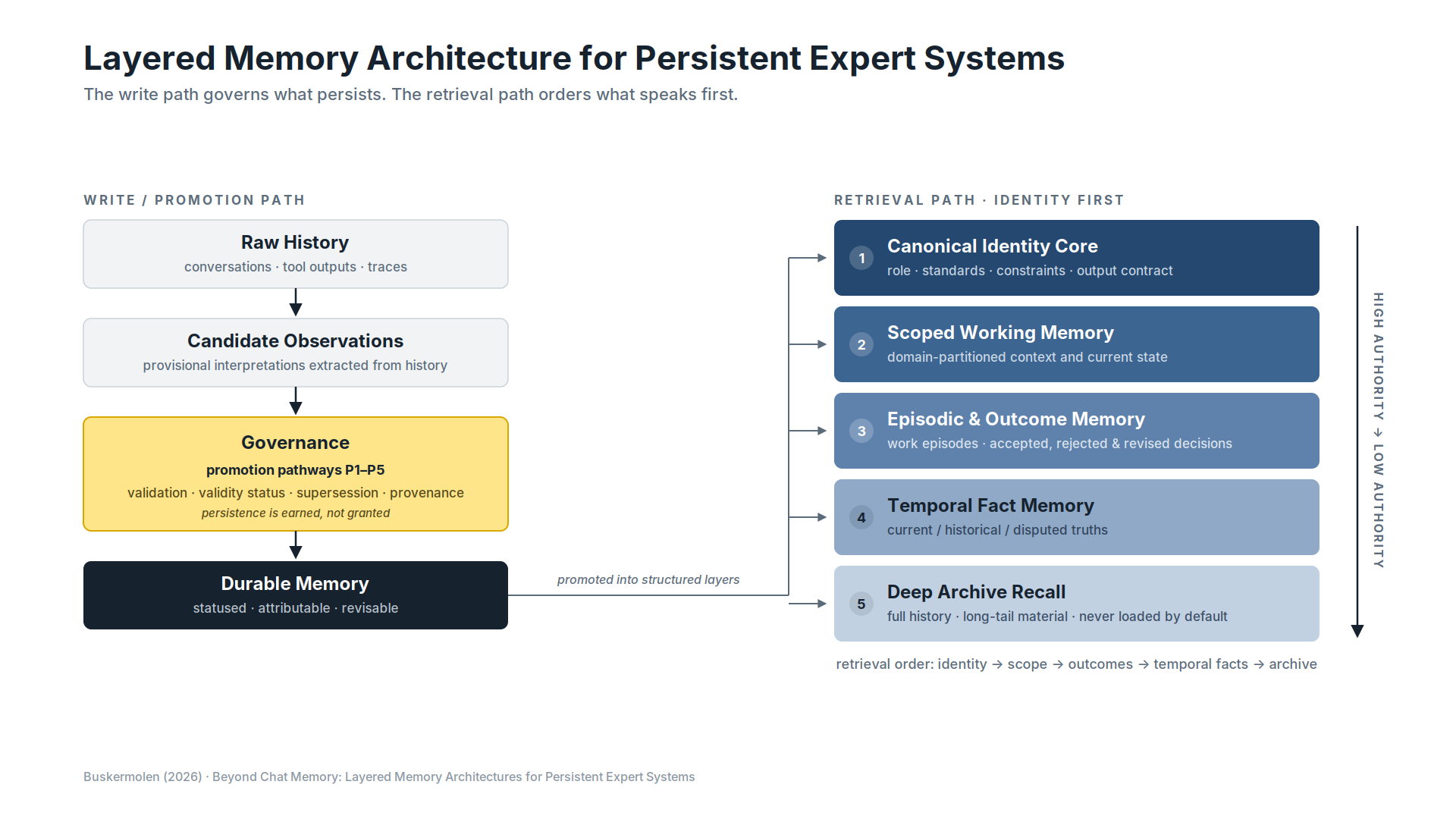
The response I proposed is a layered memory architecture. Five layers, consulted in a deliberate order. The write path governs what persists. The retrieval path orders what speaks first.
The first is a canonical identity core. Who the expert is: role, standards, constraints, output contract. Not a static system prompt, but a versioned, governed memory object that is present on every turn.
The second is scoped working memory. Memory organized by work domain, not one flat recall space. Pricing memory retrieves from the pricing scope, even when the vocabulary overlaps with positioning.
The third is episodic and outcome memory. What was worked on, and, more importantly, what was decided. Accepted work carries more weight than explored work. Rejected paths stay retrievable but stop competing as live options.
The fourth is temporal fact memory. Truths with a validity status: current, historical, disputed. Your old ICP is not deleted. It is marked as superseded, so it can never masquerade as current.
The fifth is a deep archive. Everything else. Full transcripts, long-tail material. Available, but never allowed to silently dominate.
Retrieval runs from identity to scope to history, never from history to identity. And the write path matters as much as the read path. Nothing enters durable memory just because it was mentioned. Content gets promoted, through explicit confirmation, workflow approval, or outcome validation. Persistence follows validation, not mention. I called these promotion pathways, and they are the part of the paper I would still defend most firmly.
Then the industry showed up
GBrain arrived in April. Tan's system turns markdown notes into a self-wiring knowledge graph: typed entity extraction, hybrid search, autonomous cron jobs ingesting meetings, emails, and tweets overnight. It is impressive engineering. His production brain holds over 140,000 pages, and it ships with its own retrieval benchmark.
Oracle arrived in June. The engineering blog laid out the move from RAG to memory systems: typed memory, promotion gates, scoped access control as a structural primitive, durable replayable traces. All of it backed by their broader push to make the converged database a unified, governed memory core for enterprise agents.
Reading these felt strange. Promotion gates. Typed structure. Scope as a first-class primitive. Governance over accumulation. The vocabulary I had committed to a PDF in the first week of April was showing up in a hyperscaler's engineering blog by June.
I want to be precise about what that does and does not mean. I did not beat anyone to anything. The whole field was converging, building on years of prior work in RAG, cognitive architectures, and knowledge management. What the timeline shows is narrower than a claim to priority, and more useful to me: independent reasoning from first principles landed where serious engineering organizations landed. For a solo practitioner, that is the validation that actually matters. The map was accurate.
The more interesting part is that all three of us built different things. And the differences are more instructive than the overlap.
The dial nobody is talking about
In May I wrote an addendum to the original paper, engaging GBrain's class of system directly. Working through it, one distinction kept doing all the explanatory work. It comes down to two axes.
The first is boundedness. Does the system inhabit a defined domain, or ingest everything?
The second is promotion discipline. Does content enter durable memory through governed pathways with a human on the critical path, or accumulate automatically?
GBrain is unbounded and auto-accumulating, deliberately so. It ingests your whole life and links liberally, because for a personal generalist agent, coverage is the value. A wrong fact costs little. It is one entry among thousands, filtered at retrieval time.
Oracle's memory core is substrate. It can support any position on either axis, and its pitch is that the database governs whatever you decide to persist.
A persistent expert system sits in the opposite corner from GBrain: bounded and governed. And that position is not a preference. It follows from the economics of being wrong. When a client-facing expert system retrieves a wrong fact as if it were authoritative, people rely on it. The cost is asymmetric. Governed promotion is not friction in that quadrant. It is the mechanism by which the system earns and keeps its authority.
This is the part I would want an agency owner or product builder to sit with. The boundary between governed and auto-accumulating memory is not a question of better or worse design. It is a question of design target. Judging GBrain by expert-continuity standards would be as confused as judging a compliance system by ingestion throughput. Different quadrants, different physics.
The failure mode I see most often in the wild lives in the neglected quadrant: bounded domain, weak governance. A specialist chatbot that confidently accumulates unvetted content within its declared expertise. It looks like an expert system. It drifts like a generalist. Nobody designed its memory at all.
What is still missing, from everyone
Convergence on vocabulary is not convergence on architecture. Three things from the original paper have not shown up anywhere else yet, and I think they are the parts that matter most.
The first is identity as a governed memory object. Everyone stores facts. Nobody yet treats the expert's own operating frame, its role, standards, and constraints, as versioned governed memory that participates in retrieval. GBrain's agents can rewrite their own rules when they fail. That is elegant for a personal agent and disqualifying for an expert system, because an expert that can quietly rewrite its own identity is no longer the expert you hired.
The second is outcomes as first-class memory. Retrieval systems remember what was discussed. Almost none remember what was decided: which options were accepted, which were rejected, which decisions constrain future work. Decision continuity is the single biggest gap between AI with memory and AI you can build on.
The third is evaluating for continuity, not just recall. GBrain ships a retrieval benchmark: precision and recall over a fixed corpus. That is good, necessary even. But no benchmark anywhere tests whether a system remains the same expert across sessions, prefers current truths over superseded ones, or respects decisions made three months ago. In the paper I sketched six continuity dimensions: identity stability, temporal accuracy, scope precision, decision continuity, provenance fidelity, and contradiction handling. The addendum pairs them with standard retrieval metrics in a dual-frame protocol. Retrieval metrics as the fast development signal, continuity metrics as the trustworthiness audit.
That evaluation frame is, as far as I can tell, still unclaimed territory. The vocabulary of memory engineering is commoditizing fast. It took one quarter. The measurement of continuity has not really started.
Why this matters if you run an agency
Strip away the architecture talk and the practical question is simple. Can you trust an AI system with work that accumulates?
Not can it answer questions. Can it hold your positioning steady across six months of revisions. Can it treat a decision as decided. Can you audit why it believes what it believes, and correct it at the level where the error actually lives.
Those properties do not emerge from a bigger context window or a better vector database. They are designed in, or they are absent. The industry's convergence this quarter tells me the design conversation has finally started. The gaps tell me where it goes next.
Both papers are linked below, the April original and the May addendum. If you are building in this space, or trying to decide what class of memory your AI actually needs, I would be glad to compare notes.
References
- GBrain by Garry Tan - https://github.com/garrytan/gbrain
- Oracle Developers Blog: From RAG to AI Memory Systems - https://blogs.oracle.com/developers/from-rag-to-memory-systems-building-stateful-ai-architecture
Read the paper
Originally published on LinkedIn.